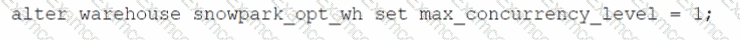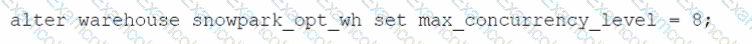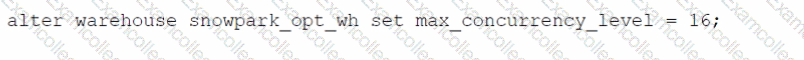Which SQL alter command will MAXIMIZE memory and compute resources for a Snowpark stored procedure when executed on the snowpark_opt_wh warehouse?
A)
B)
C)
D)
A.
Option A
B.
Option B
C.
Option C
D.
Option D
The Answer Is:
A
Good news! This question has an explanation. Do you want to see it?
Explanation:
 To maximize memory and compute resources for a Snowpark stored procedure, you need to set the MAX_CONCURRENCY_LEVEL parameter for the warehouse that executes the stored procedure. This parameter determines the maximum number of concurrent queries that can run on a single warehouse. By setting it to 16, you ensure that the warehouse can use all the available CPU cores and memory on a single node, which is the optimal configuration for Snowpark-optimized warehouses. This will improve the performance and efficiency of the stored procedure, as it will not have to share resources with other queries or nodes. The other options are incorrect because they either do not change the MAX_CONCURRENCY_LEVEL parameter, or they set it to a lower value than 16, which will reduce the memory and compute resources for the stored procedure. References:
[Snowpark-optimized Warehouses]Â 1
[Training Machine Learning Models with Snowpark Python]Â 2
What built-in Snowflake features make use of the change tracking metadata for a table? (Choose two.)
A.
The MERGE command
B.
The UPSERT command
C.
The CHANGES clause
D.
A STREAM object
E.
The CHANGE_DATA_CAPTURE command
The Answer Is:
A, D
Good news! This question has an explanation. Do you want to see it?
Explanation:
In Snowflake, the change tracking metadata for a table is utilized by the MERGE command and the STREAM object. The MERGE command uses change tracking to determine how to apply updates and inserts efficiently based on differences between source and target tables. STREAM objects, on the other hand, specifically capture and store change data, enabling incremental processing based on changes made to a table since the last stream offset was committed.
[References:Snowflake Documentation on MERGE and STREAM Objects., , ]
What transformations are supported in the below SQL statement? (Select THREE).
CREATE PIPE ... AS COPY ... FROM (...)
A.
Data can be filtered by an optional where clause.
B.
Columns can be reordered.
C.
Columns can be omitted.
D.
Type casts are supported.
E.
Incoming data can be joined with other tables.
F.
The ON ERROR - ABORT statement command can be used.
The Answer Is:
A, B, C
Good news! This question has an explanation. Do you want to see it?
Explanation:
The SQL statement is a command for creating a pipe in Snowflake, which is an object that defines the COPY INTO
statement used by Snowpipe to load data from an ingestion queue into tables1. The statement uses a subquery in the FROM clause to transform the data from the staged files before loading it into the table2.
The transformations supported in the subquery are as follows2:
Data can be filtered by an optional WHERE clause, which specifies a condition that must be satisfied by the rows returned by the subquery. For example:
SQLAI-generated code. Review and use carefully. More info on FAQ.
createpipe mypipeas
copyintomytable
from(
select*from@mystage
wherecol1='A'andcol2>10
);
Columns can be reordered, which means changing the order of the columns in the subquery to match the order of the columns in the target table. For example:
SQLAI-generated code. Review and use carefully. More info on FAQ.
createpipe mypipeas
copyintomytable (col1, col2, col3)
from(
selectcol3, col1, col2from@mystage
);
Columns can be omitted, which means excluding some columns from the subquery that are not needed in the target table. For example:
SQLAI-generated code. Review and use carefully. More info on FAQ.
createpipe mypipeas
copyintomytable (col1, col2)
from(
selectcol1, col2from@mystage
);
The other options are not supported in the subquery because2:
Type casts are not supported, which means changing the data type of a column in the subquery. For example, the following statement will cause an error:
SQLAI-generated code. Review and use carefully. More info on FAQ.
createpipe mypipeas
copyintomytable (col1, col2)
from(
selectcol1::date, col2from@mystage
);
Incoming data can not be joined with other tables, which means combining the data from the staged files with the data from another table in the subquery. For example, the following statement will cause an error:
SQLAI-generated code. Review and use carefully. More info on FAQ.
createpipe mypipeas
copyintomytable (col1, col2, col3)
from(
selects.col1, s.col2, t.col3from@mystages
joinothertable tons.col1=t.col1
);
The ON ERROR - ABORT statement command can not be used, which means aborting the entire load operation if any error occurs. This command can only be used in the COPY INTO
statement, not in the subquery. For example, the following statement will cause an error:
SQLAI-generated code. Review and use carefully. More info on FAQ.
createpipe mypipeas
copyintomytable
from(
select*from@mystage
onerror abort
);
1: CREATE PIPE | Snowflake Documentation
2: Transforming Data During a Load | Snowflake Documentation
An Architect has designed a data pipeline that Is receiving small CSV files from multiple sources. All of the files are landing in one location. Specific files are filtered for loading into Snowflake tables using the copy command. The loading performance is poor.
What changes can be made to Improve the data loading performance?
A.
Increase the size of the virtual warehouse.
B.
Create a multi-cluster warehouse and merge smaller files to create bigger files.
C.
Create a specific storage landing bucket to avoid file scanning.
D.
Change the file format from CSV to JSON.
The Answer Is:
B
Good news! This question has an explanation. Do you want to see it?
Explanation:
According to the Snowflake documentation, the data loading performance can be improved by following some best practices and guidelines for preparing and staging the data files. One of the recommendations is to aim for data files that are roughly 100-250 MB (or larger) in size compressed, as this will optimize the number of parallel operations for a load. Smaller files should be aggregated and larger files should be split to achieve this size range. Another recommendation is to use a multi-cluster warehouse for loading, as this will allow for scaling up or out the compute resources depending on the load demand. A single-cluster warehouse may not be able to handle the load concurrency and throughput efficiently. Therefore, by creating a multi-cluster warehouse and merging smaller files to create bigger files, the data loading performance can be improved. References:
A Snowflake Architect is setting up database replication to support a disaster recovery plan. The primary database has external tables.
How should the database be replicated?
A.
Create a clone of the primary database then replicate the database.
B.
Move the external tables to a database that is not replicated, then replicate the primary database.
C.
Replicate the database ensuring the replicated database is in the same region as the external tables.
D.
Share the primary database with an account in the same region that the database will be replicated to.
The Answer Is:
B
Good news! This question has an explanation. Do you want to see it?
Explanation:
Database replication is a feature that allows you to create a copy of a database in another account, region, or cloud platform for disaster recovery or business continuity purposes. However, not all database objects can be replicated. External tables are one of the exceptions, as they reference data files stored in an external stage that is not part of Snowflake. Therefore, to replicate a database that contains external tables, you need to move the external tables to a separate database that is not replicated, and then replicate the primary database that contains the other objects. This way, you can avoid replication errors and ensure consistency between the primary and secondary databases. The other options are incorrect because they either do not address the issue of external tables, or they use an alternative method that is not supported by Snowflake. You cannot create a clone of the primary database and then replicate it, as replication only works on the original database, not on its clones. You also cannot share the primary database with another account, as sharing is a different feature that does not create a copy of the database, but rather grants access to the shared objects. Finally, you do not need to ensure that the replicated database is in the same region as the external tables, as external tables can access data files stored in any region or cloud platform, as long as the stage URL is valid and accessible. References:
[Replication and Failover/Failback]Â 1
[Introduction to External Tables]Â 2
[Working with External Tables]Â 3
[Replication : How to migrate an account from One Cloud Platform or Region to another in Snowflake]Â 4
What are purposes for creating a storage integration? (Choose three.)
A.
Control access to Snowflake data using a master encryption key that is maintained in the cloud provider’s key management service.
B.
Store a generated identity and access management (IAM) entity for an external cloud provider regardless of the cloud provider that hosts the Snowflake account.
C.
Support multiple external stages using one single Snowflake object.
D.
Avoid supplying credentials when creating a stage or when loading or unloading data.
E.
Create private VPC endpoints that allow direct, secure connectivity between VPCs without traversing the public internet.
F.
Manage credentials from multiple cloud providers in one single Snowflake object.
The Answer Is:
B, C, D
Good news! This question has an explanation. Do you want to see it?
Explanation:
The purpose of creating a storage integration in Snowflake includes:
B.Store a generated identity and access management (IAM) entity for an external cloud provider- This helps in managing authentication and authorization with external cloud storage without embedding credentials in Snowflake. It supports various cloud providers like AWS, Azure, or GCP, ensuring that the identity management is streamlined across platforms.
C.Support multiple external stages using one single Snowflake object- Storage integrations allow you to set up access configurations that can be reused across multiple external stages, simplifying the management of external data integrations.
D.Avoid supplying credentials when creating a stage or when loading or unloading data- By using a storage integration, Snowflake can interact with external storage without the need to continuously manage or expose sensitive credentials, enhancing security and ease of operations.
[References:Snowflake documentation on storage integrations, found within the SnowPro Advanced: Architect course materials., , , ]
A company has an inbound share set up with eight tables and five secure views. The company plans to make the share part of its production data pipelines.
Which actions can the company take with the inbound share? (Choose two.)
A.
Clone a table from a share.
B.
Grant modify permissions on the share.
C.
Create a table from the shared database.
D.
Create additional views inside the shared database.
E.
Create a table stream on the shared table.
The Answer Is:
A, D
Good news! This question has an explanation. Do you want to see it?
Explanation:
 These two actions are possible with an inbound share, according to the Snowflake documentation and the web search results. An inbound share is a share that is created by another Snowflake account (the provider) and imported into your account (the consumer). An inbound share allows you to access the data shared by the provider, but not to modify or delete it. However, you can perform some actions with the inbound share, such as:
Clone a table from a share. You can create a copy of a table from an inbound share using the CREATE TABLE … CLONE statement. The clone will contain the same data and metadata as the original table, but it will be independent of the share. You can modify or delete the clone as you wish, but it will not reflect any changes made to the original table by the provider1.
Create additional views inside the shared database. You can create views on the tables or views from an inbound share using the CREATE VIEW statement. The views will be stored in the shared database, but they will be owned by your account. You can query the views as you would query any other view in your account, but you cannot modify or delete the underlying objects from the share2.
The other actions listed are not possible with an inbound share, because they would require modifying the share or the shared objects, which are read-only for the consumer. You cannot grant modify permissions on the share, create a table from the shared database, or create a table stream on the shared table34.
Cloning Objects from a Share | Snowflake Documentation
Creating Views on Shared Data | Snowflake Documentation
Importing Data from a Share | Snowflake Documentation
Streams on Shared Tables | Snowflake Documentation
An Architect is integrating an application that needs to read and write data to Snowflake without installing any additional software on the application server.
How can this requirement be met?
A.
Use SnowSQL.
B.
Use the Snowpipe REST API.
C.
Use the Snowflake SQL REST API.
D.
Use the Snowflake ODBC driver.
The Answer Is:
C
Good news! This question has an explanation. Do you want to see it?
Explanation:
The Snowflake SQL REST API is a REST API that you can use to access and update data in a Snowflake database. You can use this API to execute standard queries and most DDL and DML statements. This API can be used to develop custom applications and integrations that can read and write data to Snowflake without installing any additional software on the application server. Option A is not correct because SnowSQL is a command-line client that requires installation and configuration on the application server. Option B is not correct because the Snowpipe REST API is used to load data from cloud storage into Snowflake tables, not to read or write data to Snowflake. Option D is not correct because the Snowflake ODBC driver is a software component that enables applications to connect to Snowflake using the ODBC protocol, which also requires installation and configuration on the application server. References: The answer can be verified from Snowflake’s official documentation on the Snowflake SQL REST API available on their website. Here are some relevant links:
Snowflake SQL REST API | Snowflake Documentation
Introduction to the SQL API | Snowflake Documentation
Submitting a Request to Execute SQL Statements | Snowflake Documentation
Which system functions does Snowflake provide to monitor clustering information within a table (Choose two.)
A.
SYSTEM$CLUSTERING_INFORMATION
B.
SYSTEM$CLUSTERING_USAGE
C.
SYSTEM$CLUSTERING_DEPTH
D.
SYSTEM$CLUSTERING_KEYS
E.
SYSTEM$CLUSTERING_PERCENT
The Answer Is:
A, C
Good news! This question has an explanation. Do you want to see it?
Explanation:
According to the Snowflake documentation, these two system functions are provided by Snowflake to monitor clustering information within a table. A system function is a type of function that allows executing actions or returning information about the system. A clustering key is a feature that allows organizing data across micro-partitions based on one or more columns in the table. Clustering can improve query performance by reducing the number of files to scan.
SYSTEM$CLUSTERING_INFORMATION is a system function that returns clustering information, including average clustering depth, for a table based on one or more columns in the table. The function takes a table name and an optional column name or expression as arguments, and returns a JSON string with the clustering information. The clustering information includes the cluster by keys, the total partition count, the total constant partition count, the average overlaps, and the average depth1.
SYSTEM$CLUSTERING_DEPTH is a system function that returns the clustering depth for a table based on one or more columns in the table. The function takes a table name and an optional column name or expression as arguments, and returns an integer value with the clustering depth. The clustering depth is the maximum number of overlapping micro-partitions for any micro-partition in the table. A lower clustering depth indicates a better clustering2.
An Architect has chosen to separate their Snowflake Production and QA environments using two separate Snowflake accounts.
The QA account is intended to run and test changes on data and database objects before pushing those changes to the Production account. It is a requirement that all database objects and data in the QA account need to be an exact copy of the database objects, including privileges and data in the Production account on at least a nightly basis.
Which is the LEAST complex approach to use to populate the QA account with the Production account’s data and database objects on a nightly basis?
A.
1) Create a share in the Production account for each database2) Share access to the QA account as a Consumer3) The QA account creates a database directly from each share4) Create clones of those databases on a nightly basis5) Run tests directly on those cloned databases
B.
1) Create a stage in the Production account2) Create a stage in the QA account that points to the same external object-storage location3) Create a task that runs nightly to unload each table in the Production account into the stage4) Use Snowpipe to populate the QA account
C.
1) Enable replication for each database in the Production account2) Create replica databases in the QA account3) Create clones of the replica databases on a nightly basis4) Run tests directly on those cloned databases
D.
1) In the Production account, create an external function that connects into the QA account and returns all the data for one specific table2) Run the external function as part of a stored procedure that loops through each table in the Production account and populates each table in the QA account
The Answer Is:
C
Good news! This question has an explanation. Do you want to see it?
Explanation:
This approach is the least complex because it uses Snowflake’s built-in replication feature to copy the data and database objects from the Production account to the QA account. Replication is a fast and efficient way to synchronize data across accounts, regions, and cloud platforms. It also preserves the privileges and metadata of the replicated objects. By creating clones of the replica databases, the QA account can run tests on the cloned data without affecting the original data. Clones are also zero-copy, meaning they do not consume any additional storage space unless the data is modified. This approach does not require any external stages, tasks, Snowpipe, or external functions, which can add complexity and overhead to the data transfer process.
Introduction to Replication and Failover
Replicating Databases Across Multiple Accounts
Cloning Considerations
First Try then Buy
✔ ARA-C01 All Real Exam Questions✔ ARA-C01 Exam easy to use and print PDF format✔ Cover All syllabus and Objectives✔ Download Free ARA-C01 Demo (Try before Buy)✔ Free Frequent Updates✔ 100% Passing Guarantee by Exam Collection