

Snowflake ARA-R01 - SnowPro Advanced: Architect Recertification Exam
You are a snowflake architect in an organization. The business team came to to deploy an use case which requires you to load some data which they can visualize through tableau. Everyday new data comes in and the old data is no longer required.
What type of table you will use in this case to optimize cost
An Architect needs to design a Snowflake account and database strategy to store and analyze large amounts of structured and semi-structured data. There are many business units and departments within the company. The requirements are scalability, security, and cost efficiency.
What design should be used?
How is the change of local time due to daylight savings time handled in Snowflake tasks? (Choose two.)
How can the Snowpipe REST API be used to keep a log of data load history?
A company’s client application supports multiple authentication methods, and is using Okta.
What is the best practice recommendation for the order of priority when applications authenticate to Snowflake?
A new user user_01 is created within Snowflake. The following two commands are executed:
Command 1-> show grants to user user_01;
Command 2 ~> show grants on user user 01;
What inferences can be made about these commands?
A table contains five columns and it has millions of records. The cardinality distribution of the columns is shown below:
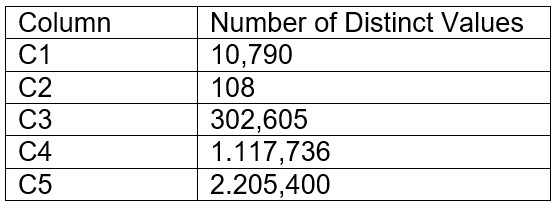
Column C4 and C5 are mostly used by SELECT queries in the GROUP BY and ORDER BY clauses. Whereas columns C1, C2 and C3 are heavily used in filter and join conditions of SELECT queries.
The Architect must design a clustering key for this table to improve the query performance.
Based on Snowflake recommendations, how should the clustering key columns be ordered while defining the multi-column clustering key?
The diagram shows the process flow for Snowpipe auto-ingest with Amazon Simple Notification Service (SNS) with the following steps:
Step 1: Data files are loaded in a stage.
Step 2: An Amazon S3 event notification, published by SNS, informs Snowpipe — by way of Amazon Simple Queue Service (SQS) - that files are ready to load. Snowpipe copies the files into a queue.
Step 3: A Snowflake-provided virtual warehouse loads data from the queued files into the target table based on parameters defined in the specified pipe.
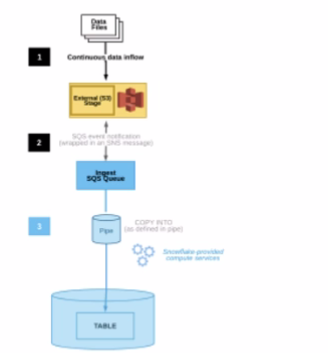
If an AWS Administrator accidentally deletes the SQS subscription to the SNS topic in Step 2, what will happen to the pipe that references the topic to receive event messages from Amazon S3?
What does a Snowflake Architect need to consider when implementing a Snowflake Connector for Kafka?
Which technique will efficiently ingest and consume semi-structured data for Snowflake data lake workloads?
