

CompTIA DY0-001 - CompTIA DataX Exam
A data scientist is attempting to identify sentences that are conceptually similar to each other within a set of text files. Which of the following is the best way to prepare the data set to accomplish this task after data ingestion?
A data scientist is performing a linear regression and wants to construct a model that explains the most variation in the data. Which of the following should the data scientist maximize when evaluating the regression performance metrics?
A data scientist uses a large data set to build multiple linear regression models to predict the likely market value of a real estate property. The selected new model has an RMSE of 995 on the holdout set and an adjusted R² of 0.75. The benchmark model has an RMSE of 1,000 on the holdout set. Which of the following is the best business statement regarding the new model?
A data analyst wants to save a newly analyzed data set to a local storage option. The data set must meet the following requirements:
Be minimal in size
Have the ability to be ingested quickly
Have the associated schema, including data types, stored with it
Which of the following file types is the best to use?
A data analyst wants to generate the most data using tables from a database. Which of the following is the best way to accomplish this objective?
Which of the following best describes the minimization of the residual term in a LASSO linear regression?
A data scientist is building a forecasting model for the price of copper. The only input in this model is the daily price of copper for the last ten years. Which of the following forecasting techniques is the most appropriate for the data scientist to use?
Which of the following layer sets includes the minimum three layers required to constitute an artificial neural network?
A data scientist is developing a model to predict the outcome of a vote for a national mascot. The choice is between tigers and lions. The full data set represents feedback from individuals representing 17 professions and 12 different locations. The following rank aggregation represents 80% of the data set:
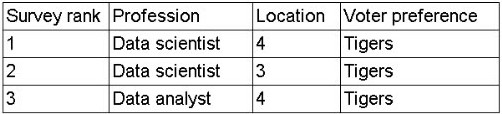
(Screenshot shows survey rankings for just two professions and a few locations, all voting for "Tigers")
Which of the following is the most likely concern about the model's ability to predict the outcome of the vote?
Which of the following distribution methods or models can most effectively represent the actual arrival times of a bus that runs on an hourly schedule?
