

Databricks Databricks-Certified-Data-Engineer-Associate - Databricks Certified Data Engineer Associate Exam
Total 176 questions
A data engineer manages multiple external tables linked to various data sources. The data engineer wants to manage these external tables efficiently and ensure that only the necessary permissions are granted to users for accessing specific external tables.
How should the data engineer manage access to these external tables?
A data engineer needs to determine whether to use the built-in Databricks Notebooks versioning or version their project using Databricks Repos.
Which of the following is an advantage of using Databricks Repos over the Databricks Notebooks versioning?
Which SQL code snippet will correctly demonstrate a Data Definition Language (DDL) operation used to create a table?
The Delta transaction log for the ‘students’ tables is shown using the ‘DESCRIBE HISTORY students’ command. A Data Engineer needs to query the table as it existed before the UPDATE operation listed in the log.
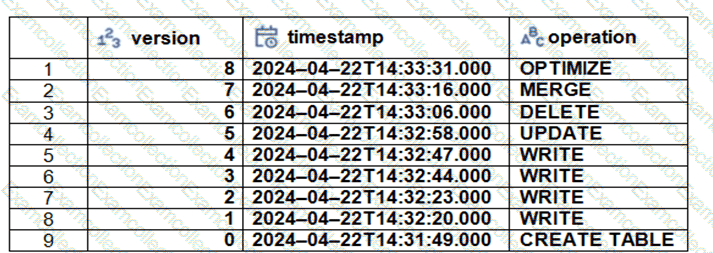
Which command should the Data Engineer use to achieve this? (Choose two.)
A data engineer has realized that the data files associated with a Delta table are incredibly small. They want to compact the small files to form larger files to improve performance.
Which of the following keywords can be used to compact the small files?
A data analysis team has noticed that their Databricks SQL queries are running too slowly when connected to their always-on SQL endpoint. They claim that this issue is present when many members of the team are running small queries simultaneously. They ask the data engineering team for help. The data engineering team notices that each of the team’s queries uses the same SQL endpoint.
Which of the following approaches can the data engineering team use to improve the latency of the team’s queries?
Which of the following describes a benefit of creating an external table from Parquet rather than CSV when using a CREATE TABLE AS SELECT statement?
A data engineer is attempting to write Python and SQL in the same command cell and is running into an error The engineer thought that it was possible to use a Python variable in a select statement.
Why does the command fail?
A data engineer is standardizing repository layouts for multiple teams adopting Databricks Asset Bundles. The engineer wants to ensure every project has a single authoritative configuration file at the repository root that defines the bundle name, targets, workspace settings, permissions, and resource mappings (for jobs and pipelines).
Which strategy should the data engineer use to meet this goal?
What is stored in a Databricks customer ' s cloud account?
