

UiPath UiPath-SAIv1 - UiPath Certified Professional Specialized AI Professional v1.0
Which type of documents can be processed using UiPath Document Understanding?
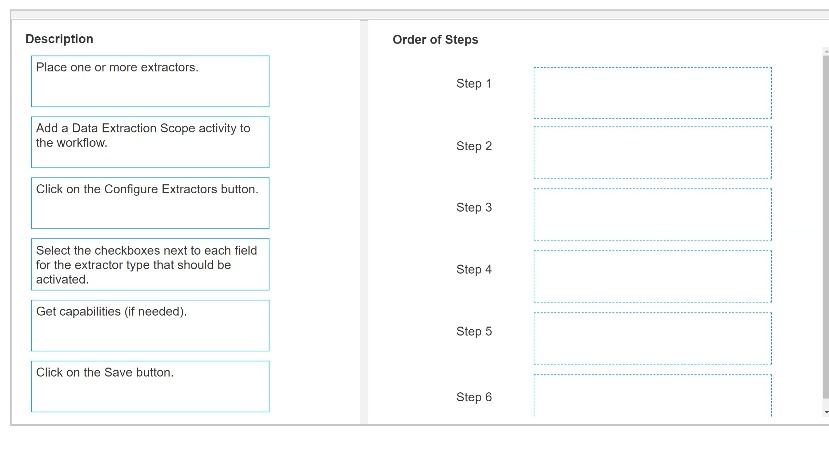
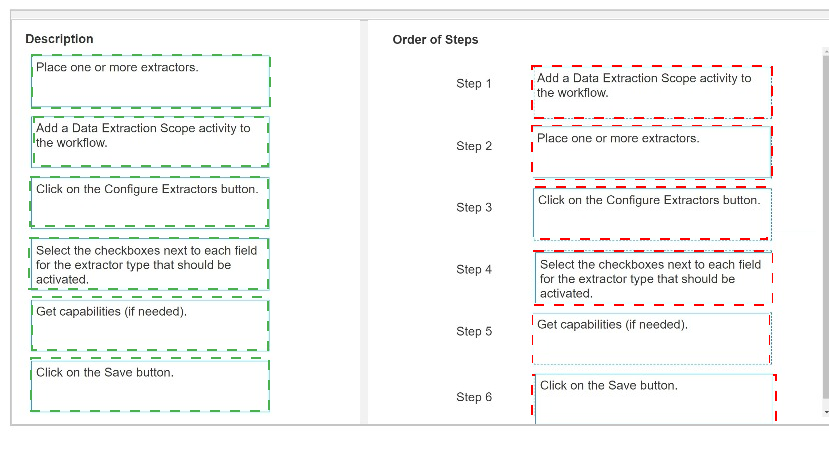
What is the correct order to Configure Extractor Wizard?
Instructions: Drag the Description found on the left and drop on the correct Step found on the right.
How can a Pipeline be scheduled?
How is the Taxonomy component used in the Document Understanding Template?
Which of the following is true when creating an ML Package in UiPath Al Center?
Which OCR (Optical Character Recognition) option is recommended to be initially utilized for document processing in a project?
Which environment variable is relevant for Evaluation pipelines?
In which of the following scenarios, the ML Classifier is the only recommended classifier to be used, according to best practice?
What does the Train stage of the Document Understanding Framework do?
Why is it important to gather and analyze data about the languages in scope?
