

Snowflake ARA-C01 - SnowPro Advanced: Architect Certification Exam
An Architect is using an event table associated with a Sales database (sales_db) to track logging and tracing of procedures and functions. The event table is also used to refresh dynamic tables.
A stored procedure causing issues resides in the Marketing database (marketing_db). Both databases are in the same Snowflake account. The Marketing database is not associated with a specific event table.
How can the Architect investigate the issue?
The Data Engineering team at a large manufacturing company needs to engineer data coming from many sources to support a wide variety of use cases and data consumer requirements which include:
1) Finance and Vendor Management team members who require reporting and visualization
2) Data Science team members who require access to raw data for ML model development
3) Sales team members who require engineered and protected data for data monetization
What Snowflake data modeling approaches will meet these requirements? (Choose two.)
A user has activated primary and secondary roles for a session.
What operation is the user prohibited from using as part of SQL actions in Snowflake using the secondary role?
A user can change object parameters using which of the following roles?
You are a snowflake architect in an organization. The business team came to to deploy an use case which requires you to load some data which they can visualize through tableau. Everyday new data comes in and the old data is no longer required.
What type of table you will use in this case to optimize cost
A retailer's enterprise data organization is exploring the use of Data Vault 2.0 to model its data lake solution. A Snowflake Architect has been asked to provide recommendations for using Data Vault 2.0 on Snowflake.
What should the Architect tell the data organization? (Select TWO).
Which command will create a schema without Fail-safe and will restrict object owners from passing on access to other users?
Based on the Snowflake object hierarchy, what securable objects belong directly to a Snowflake account? (Select THREE).
A table contains five columns and it has millions of records. The cardinality distribution of the columns is shown below:
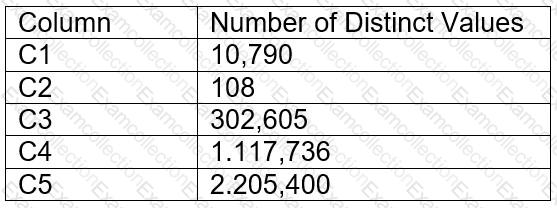
Column C4 and C5 are mostly used by SELECT queries in the GROUP BY and ORDER BY clauses. Whereas columns C1, C2 and C3 are heavily used in filter and join conditions of SELECT queries.
The Architect must design a clustering key for this table to improve the query performance.
Based on Snowflake recommendations, how should the clustering key columns be ordered while defining the multi-column clustering key?
What step will im the performance of queries executed against an external table?
