

IBM C1000-059 - IBM AI Enterprise Workflow V1 Data Science Specialist
When should median value be used instead of mean value for imputing missing data?
With only limited labeled data available how might a neural network use case be realized?
Which statement is true for naive Bayes?
If the distribution of the height of American men is approximately normal, with a mean of 69 inches and a standard deviation of 2.5 inches, then roughly 68 percent of American men have heights between and .
Which is a preferred approach for simplifying the data transformation steps in machine learning model management and maintenance?
What are two methods used to detect outliers in structured data? (Choose two.)
What is a class of machine learning problems where the algorithm is given feedback in the form of positive or negative reward in a dynamic environment?
A neural network is trained for a classification task. During training, you monitor the loss function for the train dataset and the validation dataset, along with the accuracy for the validation dataset. The goal is to get an accuracy of 95%.
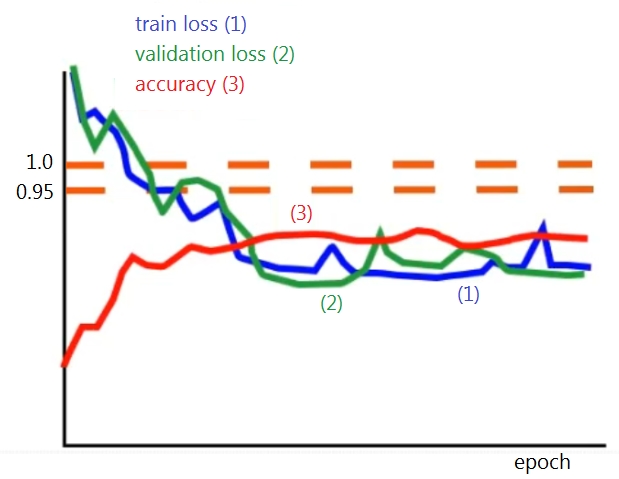
From the graph, what modification would be appropriate to improve the performance of the model?
