

Microsoft DP-100 - Designing and Implementing a Data Science Solution on Azure
You manage an Azure Machine Learning workspace.
You plan to irain a natural language processing (NLP) tew classification model in multiple languages by using Azure Machine learning Python SDK v2. You need to configure the language of the text classification job by using automated machine learning. Which method of the TextClassifkationlob class should you use?
You are evaluating a completed binary classification machine.
You need to use the precision as the evaluation metric.
Which visualization should you use?
You have an Azure Machine Learning workspace. You are connecting an Azure Data Lake Storage Gen2 account to the workspace as a data store. You need to authorize access from the workspace to the Azure Data Lake Storage Gen2 account.
What should you use?
You use Azure Machine Learning to train a model. You must use Bayesian sampling to tune hyperparameters. You need to select a ieaming_rate parameter distribution.
Which two distributions can you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
You create a batch inference pipeline by using the Azure ML SDK. You run the pipeline by using the following code:
from azureml.pipeline.core import Pipeline
from azureml.core.experiment import Experiment
pipeline = Pipeline(workspace=ws, steps=[parallelrun_step])
pipeline_run = Experiment(ws, ' batch_pipeline ' ).submit(pipeline)
You need to monitor the progress of the pipeline execution.
What are two possible ways to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.

You have an Azure Machine Learning workspace.
You have the following code:

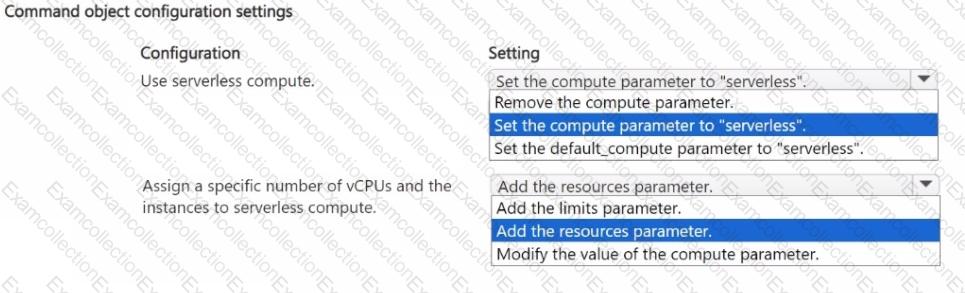
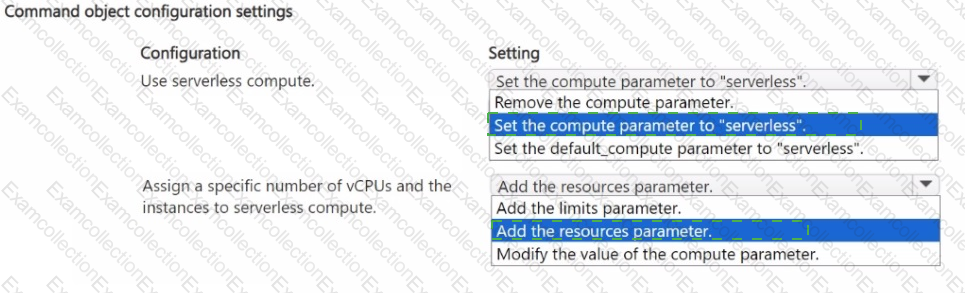
You plan to rely on serverless compute to train a model by using Azure Machine Learning Python SDK v2. The serverless compute must use a designated number of nodes of a specific virtual machine type.
You need to modify the code to run the training job according to the plan.
How should you modify the command object? To answer, select the appropriate oations in the answer area.
NOTE: Each correct selection is worth one point.
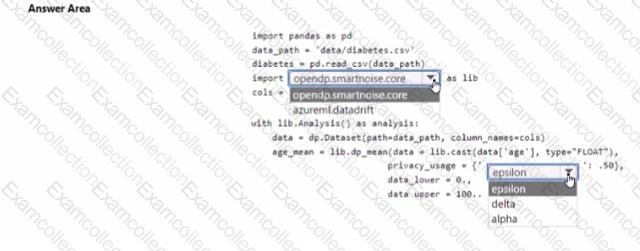
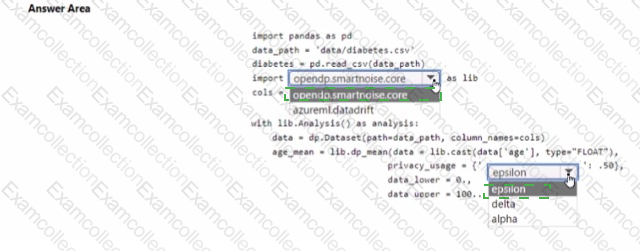
You are developing code to analyse a dataset that includes age information for a large group of diabetes patients. You create an Azure Machine Learning workspace and install all required libraries. You set the privacy budget to 1.0).
You must analyze the dataset and preserve data privacy. The code must run twice before the privacy budget is depleted.
You need to complete the code.
Which values should you use? To answer, select the appropriate options m the answer area.
NOTE: Each correct selection is worth one point.
You have an Azure Machine Learning workspace named WS1.
You plan to use the Responsible Al dashboard to assess MLflow models that you will register in WS1.
You need to identify the library you should use to register the MLflow models.
Which library should you use?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it as a result, these questions will not appear in the review screen.
You train and register an Azure Machine Learning model.
You plan to deploy the model to an online end point.
You need to ensure that applications will be able to use the authentication method with a non-expiring artifact to access the model.
Solution:
Create a Kubernetes online endpoint and set the value of its auth-mode parameter to amyl Token. Deploy the model to the online endpoint.
Does the solution meet the goal?
You use Azure Machine Learning Studio to build a machine learning experiment.
You need to divide data into two distinct datasets.
Which module should you use?
