

Microsoft DP-600 - Implementing Analytics Solutions Using Microsoft Fabric
Which syntax should you use in a notebook to access the Research division data for Productlinel?
A)

B)
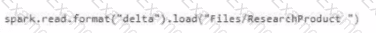
C)

D)

You need to refresh the Orders table of the Online Sales department. The solution must meet the semantic model requirements. What should you include in the solution?
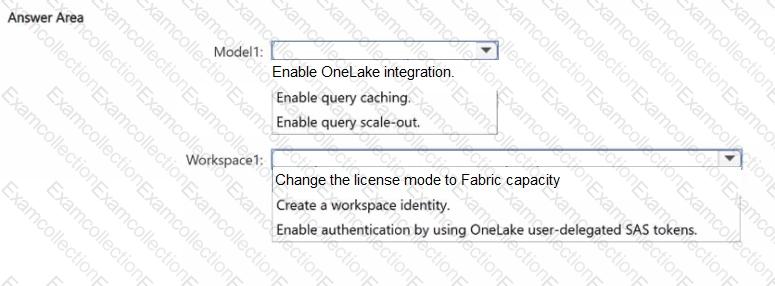
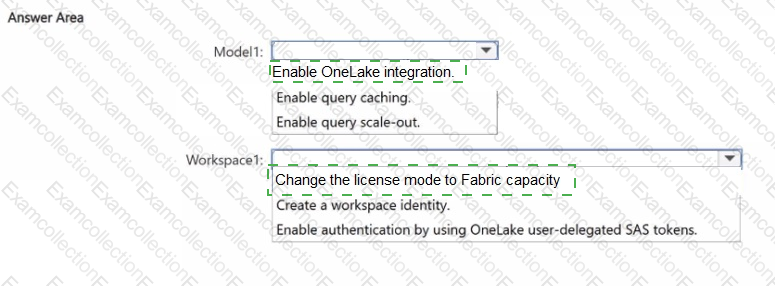
You have a Fabric workspace named Workspacel that uses the Premium Per User (PPU) license mode and contains a semantic model named Model!.
Large semantic model storage format is selected for Model 1.
You need to ensure that tables imported into Modell are written automatically to Delta tables in OneLake.
What should you do for Modell and Workspacel? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have a Fabric tenant that contains two workspaces named Woritspace1 and Workspace2. Workspace1 contains a lakehouse named Lakehouse1. Workspace2 contains a lakehouse named Lakehouse2. Lakehouse! contains a table named dbo.Sales. Lakehouse2 contains a table named dbo.Customers.
You need to ensure that you can write queries that reference both dbo.Sales and dbo.Customers in the same SQL query without making additional copies of the tables.
What should you use?
You have a Fabric workspace named Workspace1 that contains a dataflow named Dataflow1. Dataflow1 returns 500 rows of data.
You need to identify the min and max values for each column in the query results.
Which three Data view options should you select? Each correct answer presents part of the solution.
NOTE: Each correct answer is worth one point.
You have a Fabric tenant that contains a new semantic model in OneLake.
You use a Fabric notebook to read the data into a Spark DataFrame.
You need to evaluate the data to calculate the min, max, mean, and standard deviation values for all the string and numeric columns.
Solution: You use the following PySpark expression:
df .sumary ()
Does this meet the goal?
You have a Fabric warehouse that contains a table named Sales.Orders. Sales.Orders contains the following columns.
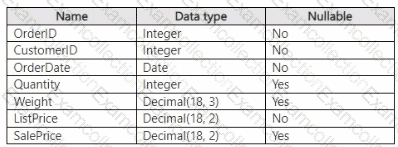
You need to write a T-SQL query that will return the following columns.
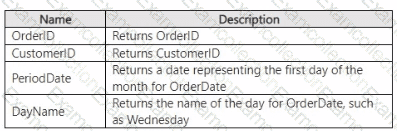
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
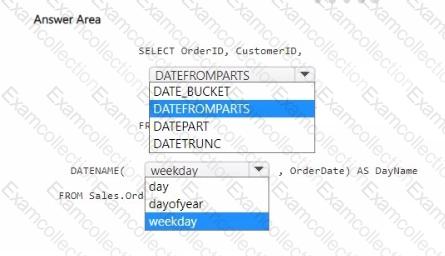
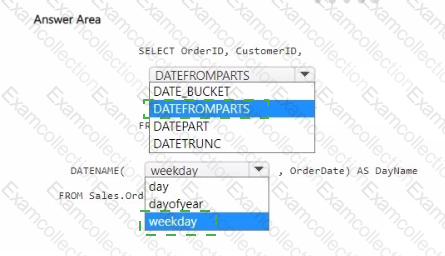
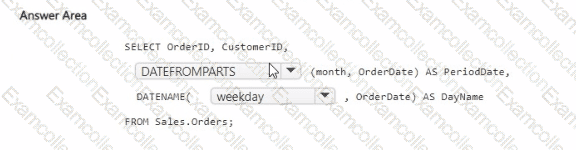
You have a Fabric workspace that contains a large warehouse.
You plan to create a lakehouse named Lakehousel for a sales dataset. Lakehousel will contain the following tables:
• Sales: Contains sales transactions
• Stores: Contains a unique list of store names and locations
• Loyalty: Contains a list of customers and their preferred stores
• Customers: Contains a unique list of customer names and addresses
• Products: Contains a unique list of available products and their descriptions
You need to configure a star schema for Lakehousel.
Which table should you define as the fact table, and which type of relationship should you configure from the Sales table to the Customers table? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


You have a Fabric workspace named Workspace1.
Workspace1 contains multiple semantic models, including a model named Model1. Model1 is updated by using an XMLA endpoint.
You need to increase the speed of the write operations of the XMLA endpoint.
What should you do?
You have a Fabric tenant that contains a warehouse named DW1 and a lakehouse named LH1. DW1 contains a table named Sales.Product. LH1 contains a table named Sales.Orders.
You plan to schedule an automated process that will create a new point-in-time (PIT) table named Sales.ProductOrder in DW1. Sales.ProductOrder will be built by using the results of a query that will join Sales.Product and Sales.Orders.
You need to ensure that the types of columns in Sales. ProductOrder match the column types in the source tables. The solution must minimize the number of operations required to create the new table.
Which operation should you use?
