

Microsoft DP-700 - Implementing Data Engineering Solutions Using Microsoft Fabric
You need to recommend a method to populate the POS1 data to the lakehouse medallion layers.
What should you recommend for each layer? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

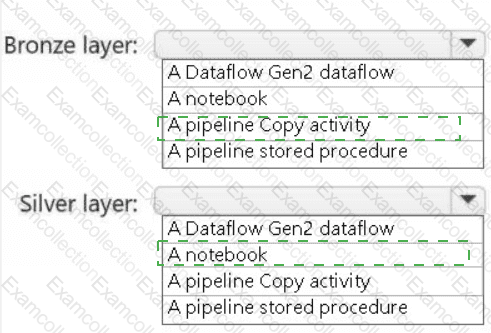
 A screenshot of a computer Description automatically generated
A screenshot of a computer Description automatically generatedYou need to ensure that usage of the data in the Amazon S3 bucket meets the technical requirements.
What should you do?
You need to schedule the population of the medallion layers to meet the technical requirements.
What should you do?
You need to recommend a solution for handling old files. The solution must meet the technical requirements. What should you include in the recommendation?
You need to ensure that WorkspaceA can be configured for source control. Which two actions should you perform?
Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
You need to ensure that the data engineers are notified if any step in populating the lakehouses fails. The solution must meet the technical requirements and minimize development effort.
What should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
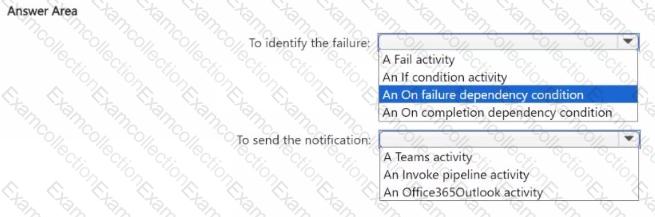
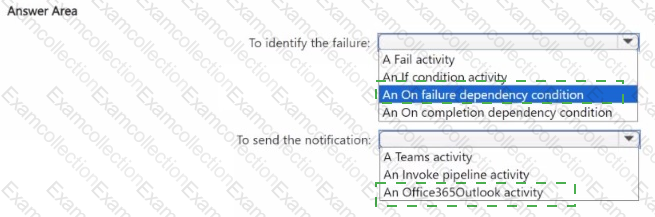
You need to ensure that the data analysts can access the gold layer lakehouse.
What should you do?
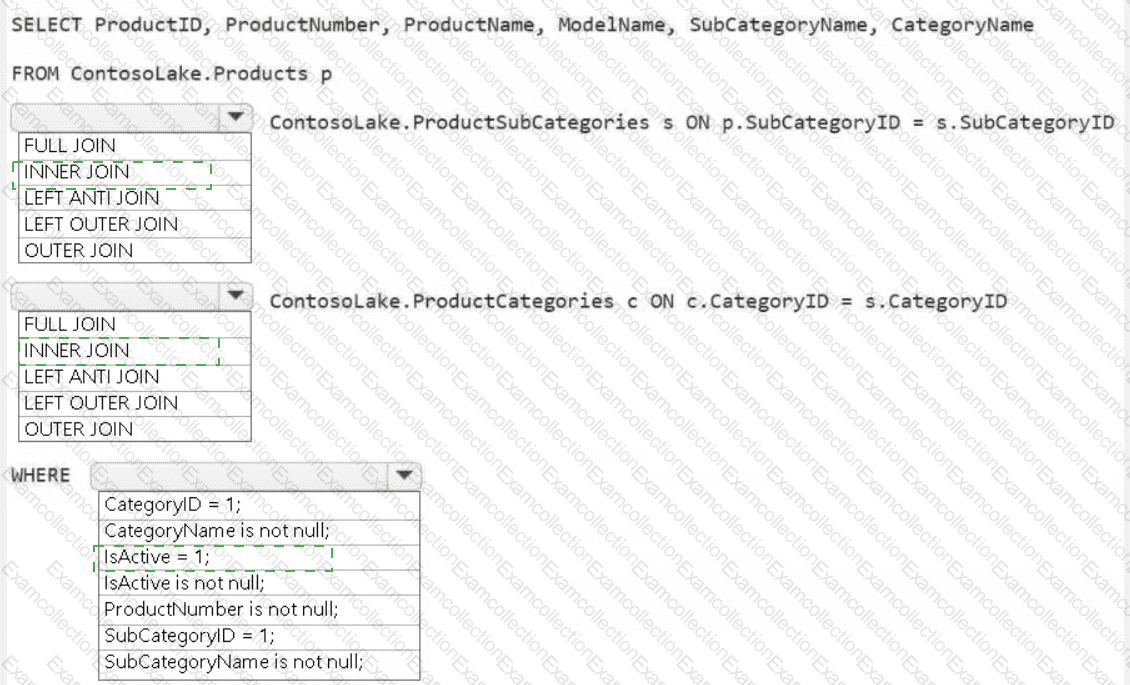
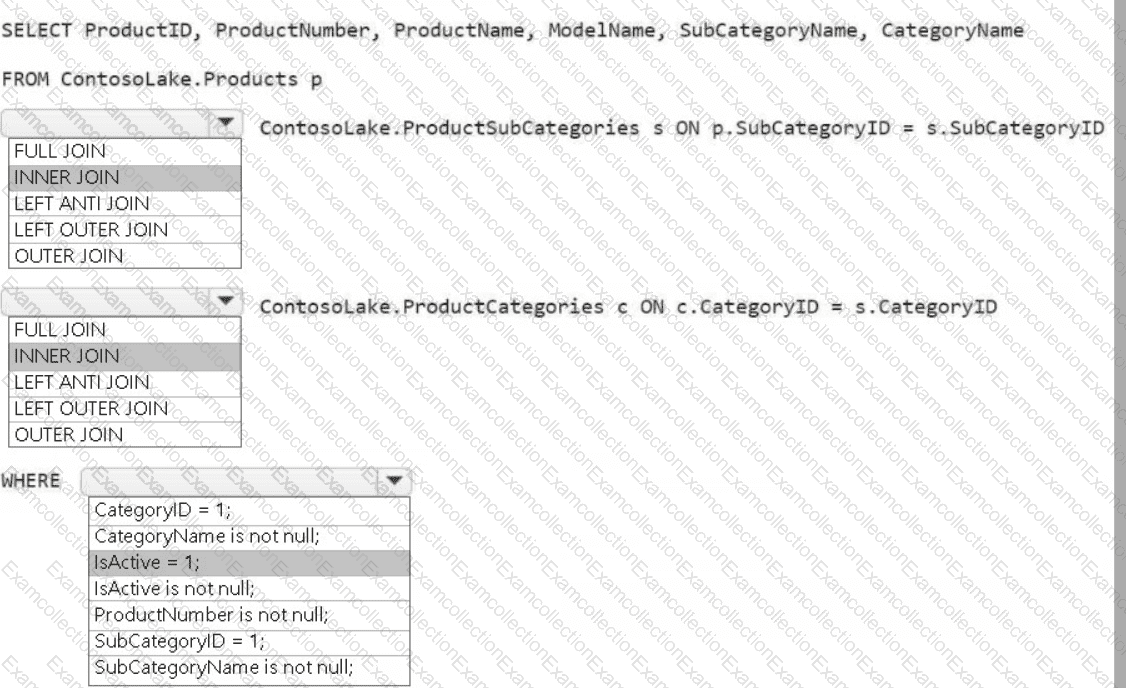
You need to create the product dimension.
How should you complete the Apache Spark SQL code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
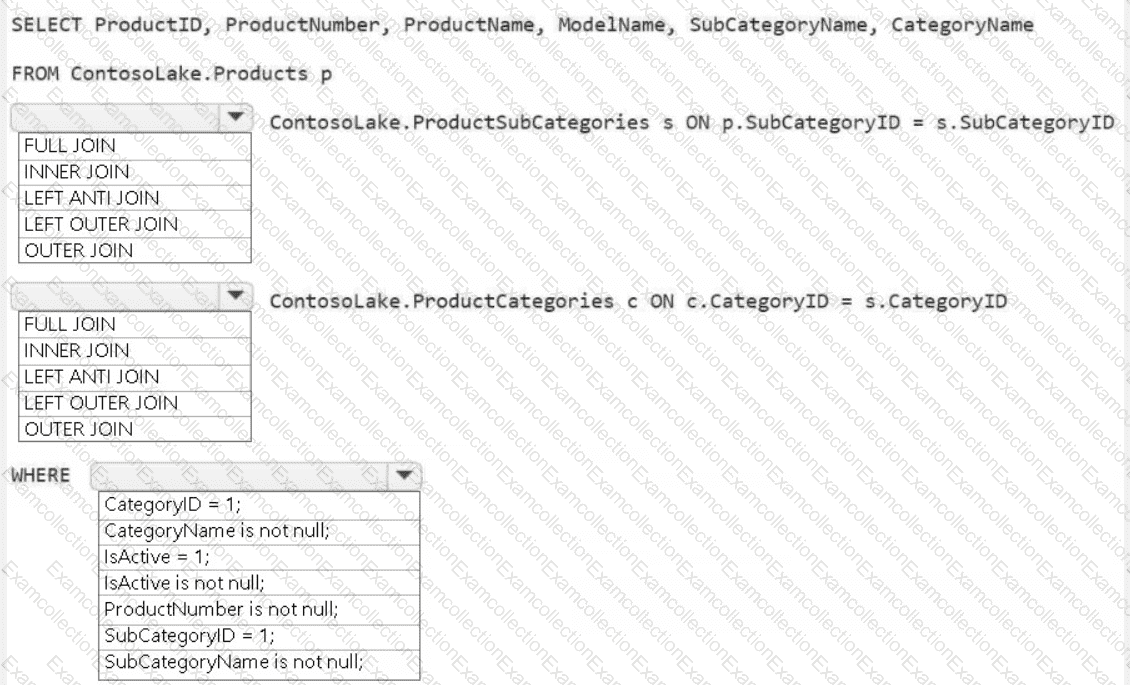
 A screenshot of a computer Description automatically generated
A screenshot of a computer Description automatically generatedYou need to recommend a solution to resolve the MAR1 connectivity issues. The solution must minimize development effort. What should you recommend?
You need to populate the MAR1 data in the bronze layer.
Which two types of activities should you include in the pipeline? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
