

Microsoft DP-700 - Implementing Data Engineering Solutions Using Microsoft Fabric
You need to resolve the sales data issue. The solution must minimize the amount of data transferred.
What should you do?
What should you do to optimize the query experience for the business users?
You need to ensure that the authors can see only their respective sales data.
How should you complete the statement? To answer, drag the appropriate values the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content
NOTE: Each correct selection is worth one point.


You need to create a workflow for the new book cover images.
Which two components should you include in the workflow? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You need to implement the solution for the book reviews.
Which should you do?
You need to ensure that processes for the bronze and silver layers run in isolation How should you configure the Apache Spark settings?
You have an Azure event hub. Each event contains the following fields:
BikepointID
Street
Neighbourhood
Latitude
Longitude
No_Bikes
No_Empty_Docks
You need to ingest the events. The solution must only retain events that have a Neighbourhood value of Chelsea, and then store the retained events in a Fabric lakehouse.
What should you use?
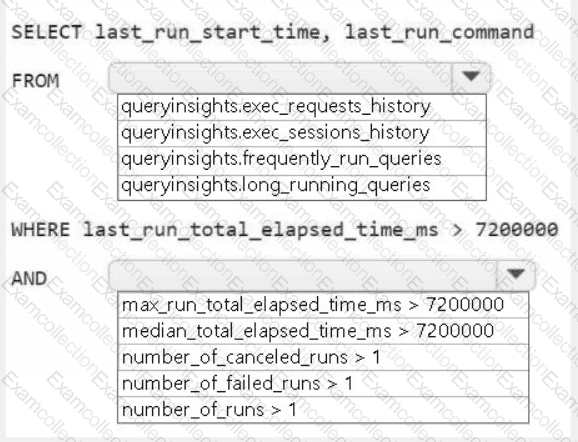
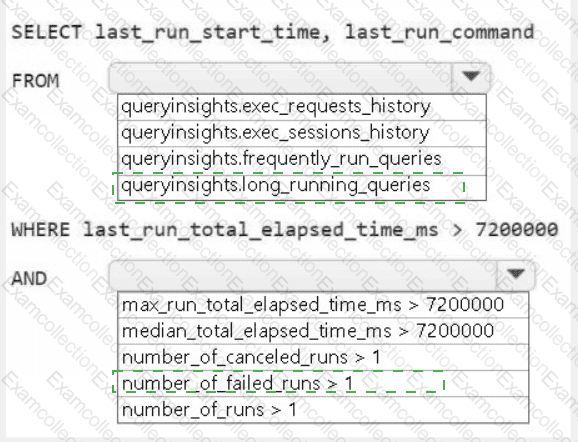
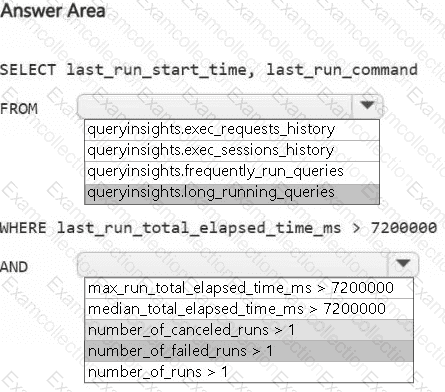
HOTSPOT
You need to troubleshoot the ad-hoc query issue.
How should you complete the statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
 A screenshot of a computer Description automatically generated
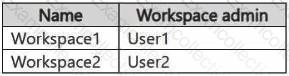
A screenshot of a computer Description automatically generatedYou have three users named User1, User2, and User3.
You have the Fabric workspaces shown in the following table.
You have a security group named Group1 that contains User1 and User3.
The Fabric admin creates the domains shown in the following table.

User1 creates a new workspace named Workspace3.
You add Group1 to the default domain of Domain1.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.


You have a Fabric F32 capacity that contains a workspace. The workspace contains a warehouse named DW1 that is modelled by using MD5 hash surrogate keys.
DW1 contains a single fact table that has grown from 200Â million rows to 500Â million rows during the past year.
You have Microsoft Power BI reports that are based on Direct Lake. The reports show year-over-year values.
Users report that the performance of some of the reports has degraded over time and some visuals show errors.
You need to resolve the performance issues. The solution must meet the following requirements:
Provide the best query performance.
Minimize operational costs.
Which should you do?
