

Databricks Databricks-Certified-Associate-Developer-for-Apache-Spark-3.5 - Databricks Certified Associate Developer for Apache Spark 3.5 – Python
Total 136 questions
A developer is running Spark SQL queries and notices underutilization of resources. Executors are idle, and the number of tasks per stage is low.
What should the developer do to improve cluster utilization?
A data engineer needs to persist a file-based data source to a specific location. However, by default, Spark writes to the warehouse directory (e.g., /user/hive/warehouse). To override this, the engineer must explicitly define the file path.
Which line of code ensures the data is saved to a specific location?
Options:
Given this code:

.withWatermark("event_time", "10 minutes")
.groupBy(window("event_time", "15 minutes"))
.count()
What happens to data that arrives after the watermark threshold?
Options:
A data engineer needs to write a DataFrame df to a Parquet file, partitioned by the column country, and overwrite any existing data at the destination path.
Which code should the data engineer use to accomplish this task in Apache Spark?
Given this view definition:
df.createOrReplaceTempView("users_vw")
Which approach can be used to query the users_vw view after the session is terminated?
Options:
1 of 55. A data scientist wants to ingest a directory full of plain text files so that each record in the output DataFrame contains the entire contents of a single file and the full path of the file the text was read from.
The first attempt does read the text files, but each record contains a single line. This code is shown below:
txt_path = "/datasets/raw_txt/*"
df = spark.read.text(txt_path) # one row per line by default
df = df.withColumn("file_path", input_file_name()) # add full path
Which code change can be implemented in a DataFrame that meets the data scientist's requirements?
A Spark DataFrame df is cached using the MEMORY_AND_DISK storage level, but the DataFrame is too large to fit entirely in memory.
What is the likely behavior when Spark runs out of memory to store the DataFrame?
Which Spark configuration controls the number of tasks that can run in parallel on the executor?
Options:
A data scientist is analyzing a large dataset and has written a PySpark script that includes several transformations and actions on a DataFrame. The script ends with a collect() action to retrieve the results.
How does Apache Sparkâ„¢'s execution hierarchy process the operations when the data scientist runs this script?
A developer wants to refactor some older Spark code to leverage built-in functions introduced in Spark 3.5.0. The existing code performs array manipulations manually. Which of the following code snippets utilizes new built-in functions in Spark 3.5.0 for array operations?

A)

B)

C)
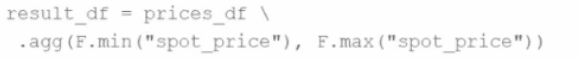
D)

