

Databricks Databricks-Certified-Data-Engineer-Associate - Databricks Certified Data Engineer Associate Exam
Total 176 questions
A data engineer needs to create a table in Databricks using data from their organization ' s existing SQLite database. They run the following command:
CREATE TABLE jdbc_customer360
USING
OPTIONS (
url " jdbc:sqlite:/customers.db " , dbtable " customer360 "
)
Which line of code fills in the above blank to successfully complete the task?
A data engineer wants to create an external table in Databricks that references data stored in an Azure Data Lake Storage (ADLS) location. The goal is to enable Databricks to access and query this external data without moving it into Databricks-managed storage.
Which step should the data engineer take to successfully create the external table?
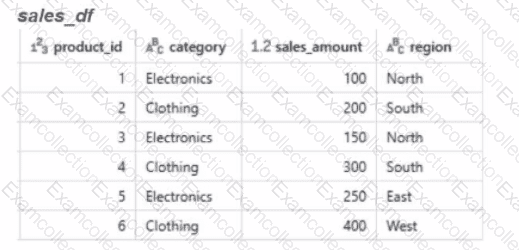
Calculate the total sales amount for each region and store the results in a new dataframe called region_sales.
Given the expected result:
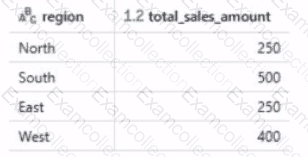
Which code will generate the expected result?
Which of the following SQL keywords can be used to convert a table from a long format to a wide format?
A data engineer is developing an ETL process based on Spark SQL. The execution fails. The data engineer checks the Spark Ul and can see the ERRORS as follows:

Which two corrective actions should the data engineer perform to resolve this issue?
Choose 2 answers - (Q) Narrow the filters in order to collect less data in the query
Which of the following tools is used by Auto Loader process data incrementally?
Which of the following is hosted completely in the control plane of the classic Databricks architecture?
Which TWO items are characteristics of the Gold Layer?
Choose 2 answers
A data engineer wants to schedule their Databricks SQL dashboard to refresh every hour, but they only want the associated SQL endpoint to be running when it is necessary. The dashboard has multiple queries on multiple datasets associated with it. The data that feeds the dashboard is automatically processed using a Databricks Job.
Which of the following approaches can the data engineer use to minimize the total running time of the SQL endpoint used in the refresh schedule of their dashboard?
An organization needs to share a dataset stored in its Databricks Unity Catalog with an external partner who uses a different data platform that is not Databricks. The goal is to maintain data security and ensure the partner can access the data efficiently.
Which method should the data engineer use to securely share the dataset with the external partner?
