

Databricks Databricks-Certified-Professional-Data-Scientist - Databricks Certified Professional Data Scientist Exam
Total 138 questions
You are working on a Data Science project and during the project you have been gibe a responsibility to interview all the stakeholders in the project. In which phase of the project you are?
Select the sequence of the developing machine learning applications
A) Analyze the input data
B) Prepare the input data
C) Collect data
D) Train the algorithm
E) Test the algorithm
F) Use It
Assume some output variable "y" is a linear combination of some independent input variables "A" plus some independent noise "e". The way the independent variables are combined is defined by a parameter vector B y=AB+e where X is an m x n matrix. B is a vector of n unknowns, and b is a vector of m values. Assuming that m is not equal to n and the columns of X are linearly independent, which expression correctly solves for B?
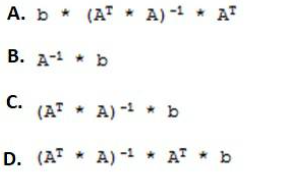
Question-34. Stories appear in the front page of Digg as they are "voted up" (rated positively) by the community. As the community becomes larger and more diverse, the promoted stories can better reflect the average interest of the community members. Which of the following technique is used to make such recommendation engine?
Select the correct statement which applies to K-Nearest Neighbors
Classification and regression are examples of___________.
Your company has organized an online campaign for feedback on product quality and you have all the responses for the product reviews, in the response form people have check box as well as text field. Now you know that people who do not fill in or write non-dictionary word in the text field are not considered valid feedback. People who fill in text field with proper English words are considered valid response. Which of the following method you should not use to identify whether the response is valid or not?
Spam filtering of the emails is an example of
You are creating a model for the recommending the book at Amazon.com, so which of the following recommender system you will use you don't have cold start problem?
You are using k-means clustering to classify heart patients for a hospital. You have chosen Patient Sex, Height, Weight, Age and Income as measures and have used 3 clusters. When you create a pair-wise plot of the clusters, you notice that there is significant overlap between the clusters. What should you do?
