

Databricks Databricks-Certified-Professional-Data-Scientist - Databricks Certified Professional Data Scientist Exam
Total 138 questions
What are the advantages of the mutual information over the Pearson correlation for text classification problems?
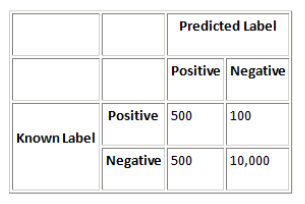
Consider the following confusion matrix for a data set with 600 out of 11,100 instances positive:
In this case, Precision = 50%, Recall = 83%, Specificity = 95%, and Accuracy = 95%.
Select the correct statement
A fruit may be considered to be an apple if it is red, round, and about 3" in diameter. A naive Bayes classifier considers each of these features to contribute independently to the probability that this fruit is an apple, regardless of the
A problem statement is given as below
Hospital records show that of patients suffering from a certain disease, 75% die of it. What is the probability that of 6 randomly selected patients, 4 will recover?
Which of the following model will you use to solve it.
Which analytical method is considered unsupervised?

may have a trend component that is quadratic in nature. Which pattern of data will indicate that the trend in the time series data is quadratic in nature?
Suppose A, B , and C are events. The probability of A given B , relative to P(|C), is the same as the probability of A given B and C (relative to P ). That is,
Question-3: In machine learning, feature hashing, also known as the hashing trick (by analogy to the kernel trick), is a fast and space-efficient way of vectorizing features (such as the words in a language), i.e., turning arbitrary features into indices in a vector or matrix. It works by applying a hash function to the features and using their hash values modulo the number of features as indices directly, rather than looking the indices up in an associative array. So what is the primary reason of the hashing trick for building classifiers?
Which of the following skills a data scientists required?
Which of the following is not a correct application for the Classification?
Google Adwords studies the number of men, and women, clicking the advertisement on search
engine during the midnight for an hour each day.
Google find that the number of men that click can be modeled as a random variable with distribution
Poisson(X), and likewise the number of women that click as Poisson(Y).
What is likely to be the best model of the total number of advertisement clicks during the midnight for an hour ?
