

Databricks Databricks-Certified-Professional-Data-Scientist - Databricks Certified Professional Data Scientist Exam
Total 138 questions
You have data of 10.000 people who make the purchasing from a specific grocery store. You also have their income detail in the data. You have created 5 clusters using this data. But in one of the cluster you see that only 30 people are falling as below 30, 2400, 2600, 2700, 2270 etc."
What would you do in this case?
Refer to Exhibit
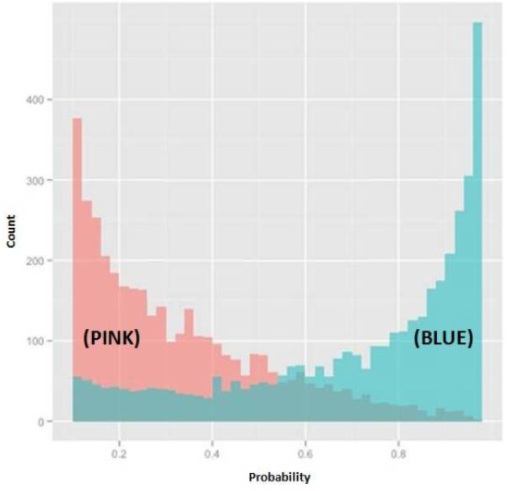
In the exhibit, the x-axis represents the derived probability of a borrower defaulting on a loan. Also in the exhibit, the pink represents borrowers that are known to have not defaulted on their loan, and the blue represents borrowers that are known to have defaulted on their loan. Which analytical method could produce the probabilities needed to build this exhibit?
In which of the scenario you can use the regression to predict the values
In which phase of the data analytics lifecycle do Data Scientists spend the most time in a project?
Which of the following is a correct example of the target variable in regression (supervised learning)?
In statistics, maximum-likelihood estimation (MLE) is a method of estimating the parameters of a statistical model. When applied to a data set and given a statistical model, maximum-likelihood estimation provides estimates for the model's parameters and the normalizing constant usually ignored in MLEs because
Suppose that we are interested in the factors that influence whether a political candidate wins an election. The outcome (response) variable is binary (0/1); win or lose. The predictor variables of interest are the amount of money spent on the campaign, the amount of time spent campaigning negatively and whether or not the candidate is an incumbent.
Above is an example of
A data scientist is asked to implement an article recommendation feature for an on-line magazine.
The magazine does not want to use client tracking technologies such as cookies or reading history. Therefore, only the style and subject matter of the current article is available for making recommendations. All of the magazine's articles are stored in a database in a format suitable for analytics.
Which method should the data scientist try first?
RMSE is a useful metric for evaluating which types of models?
What type of output generated in case of linear regression?
