

Amazon Web Services MLA-C01 - AWS Certified Machine Learning Engineer - Associate
An ML engineer needs to use an ML model to predict the price of apartments in a specific location.
Which metric should the ML engineer use to evaluate the model ' s performance?
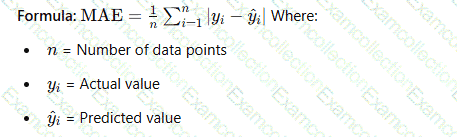
A company is building a near real-time data analytics application to detect anomalies and failures for industrial equipment. The company has thousands of IoT sensors that send data every 60 seconds. When new versions of the application are released, the company wants to ensure that application code bugs do not prevent the application from running.
Which solution will meet these requirements?
An ML engineer is using Amazon SageMaker Canvas to build a custom ML model from an imported dataset. The model must make continuous numeric predictions based on 10 years of data.
Which metric should the ML engineer use to evaluate the model’s performance?
A healthcare analytics company wants to segment patients into groups that have similar risk factors to develop personalized treatment plans. The company has a dataset that includes patient health records, medication history, and lifestyle changes. The company must identify the appropriate algorithm to determine the number of groups by using hyperparameters.
Which solution will meet these requirements?
A company has used Amazon SageMaker to deploy a predictive ML model in production. The company is using SageMaker Model Monitor on the model. After a model update, an ML engineer notices data quality issues in the Model Monitor checks.
What should the ML engineer do to mitigate the data quality issues that Model Monitor has identified?
A company is using Amazon SageMaker AI to develop a credit risk assessment model. During model validation, the company finds that the model achieves 82% accuracy on the validation data. However, the model achieved 99% accuracy on the training data. The company needs to address the model accuracy issue before deployment.
Which solution will meet this requirement?
A company ' s ML engineer has deployed an ML model for sentiment analysis to an Amazon SageMaker endpoint. The ML engineer needs to explain to company stakeholders how the model makes predictions.
Which solution will provide an explanation for the model ' s predictions?
A company collects customer data every day. The company stores the data as compressed files in an Amazon S3 bucket that is partitioned by date. Every month, analysts download the data, process the data to check the data quality, and then upload the data to Amazon QuickSight dashboards.
An ML engineer needs to implement a solution to automatically check the data quality before the data is sent to QuickSight.
Which solution will meet these requirements with the LEAST operational overhead?
A company runs an ML model on Amazon SageMaker AI. The company uses an automatic process that makes API calls to create training jobs for the model. The company has new compliance rules that prohibit the collection of aggregated metadata from training jobs.
Which solution will prevent SageMaker AI from collecting metadata from the training jobs?
An ML engineer is setting up an Amazon SageMaker AI pipeline for an ML model. The pipeline must automatically initiate a retraining job if any data drift is detected.
How should the ML engineer set up the pipeline to meet this requirement?
