

Databricks Databricks-Certified-Professional-Data-Engineer - Databricks Certified Data Engineer Professional Exam
Total 202 questions
The data science team has requested assistance in accelerating queries on free form text from user reviews. The data is currently stored in Parquet with the below schema:
item_id INT, user_id INT, review_id INT, rating FLOAT, review STRING
The review column contains the full text of the review left by the user. Specifically, the data science team is looking to identify if any of 30 key words exist in this field.
A junior data engineer suggests converting this data to Delta Lake will improve query performance.
Which response to the junior data engineer s suggestion is correct?
A Delta Lake table representing metadata about content posts from users has the following schema:
user_id LONG
post_text STRING
post_id STRING
longitude FLOAT
latitude FLOAT
post_time TIMESTAMP
date DATE
Based on the above schema, which column is a good candidate for partitioning the Delta Table?
A data ingestion task requires a one-TB JSON dataset to be written out to Parquet with a target part-file size of 512 MB. Because Parquet is being used instead of Delta Lake, built-in file-sizing features such as Auto-Optimize and Auto-Compaction cannot be used.
Which strategy will yield the best performance without shuffling data?
A Databricks SQL dashboard has been configured to monitor the total number of records present in a collection of Delta Lake tables using the following query pattern:
SELECT COUNT (*) FROM table -
Which of the following describes how results are generated each time the dashboard is updated?
A streaming video analytics team ingests billions of events daily into a Unity Catalog-managed Delta table video_events . Analysts run ad-hoc point-lookup queries on columns like user_id, campaign_id, and region. The team manually runs OPTIMIZE video_events ZORDER BY (user_id, campaign_id, region), but still sees poor performance on recent data and dislikes the operational overhead. The team wants a hands-off way to keep hot columns co-located as query patterns evolve.
A junior data engineer seeks to leverage Delta Lake ' s Change Data Feed functionality to create a Type 1 table representing all of the values that have ever been valid for all rows in a bronze table created with the property delta.enableChangeDataFeed = true . They plan to execute the following code as a daily job:
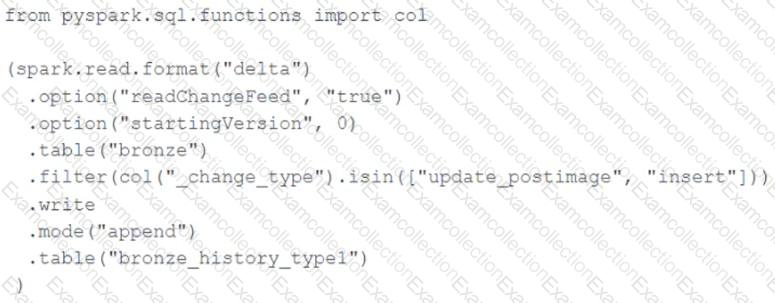
Which statement describes the execution and results of running the above query multiple times?
A data engineer, User A, has promoted a new pipeline to production by using the REST API to programmatically create several jobs. A DevOps engineer, User B, has configured an external orchestration tool to trigger job runs through the REST API. Both users authorized the REST API calls using their personal access tokens.
Which statement describes the contents of the workspace audit logs concerning these events?
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFrame df . The pipeline needs to calculate the average humidity and average temperature for each non-overlapping five-minute interval. Events are recorded once per minute per device.
Streaming DataFrame df has the following schema:
" device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT "
Code block:

Choose the response that correctly fills in the blank within the code block to complete this task.
The DevOps team has configured a production workload as a collection of notebooks scheduled to run daily using the Jobs UI. A new data engineering hire is onboarding to the team and has requested access to one of these notebooks to review the production logic.
What are the maximum notebook permissions that can be granted to the user without allowing accidental changes to production code or data?
A junior developer complains that the code in their notebook isn ' t producing the correct results in the development environment. A shared screenshot reveals that while they ' re using a notebook versioned with Databricks Repos, they ' re using a personal branch that contains old logic. The desired branch named dev-2.3.9 is not available from the branch selection dropdown.
Which approach will allow this developer to review the current logic for this notebook?
